随着边缘智能需求的激增,在资源受限的设备端直接进行模型训练,以适应动态变化的环境,已成为重要趋势。神经拟态计算被认为是实现高效能边缘智能的关键路径,但现有神经拟态芯片架构普遍缺乏直接训练深度脉冲神经网络的能力。近日,我院田永鸿教授团队联合鹏城实验室、中科院自动化所等单位,发表了题为“A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks”的研究成果。团队提出了首个支持反向传播训练深度脉冲神经网络的多核神经拟态架构,在能效比、训练并行度和内存访问效率等关键指标上展现出明显优势,为实现可学习、自适应的边缘智能奠定了坚实的硬件基础。

论文链接:https://www.nature.com/articles/s41467-026-70586-x
当前,脉冲神经网络作为第三代神经网络模型的代表,凭借其事件驱动与稀疏计算的特性,展现出显著的能效潜力。然而,如何在与之适配的神经拟态芯片上,高效实现成熟的反向传播训练算法,是该领域的重要挑战。现有芯片往往难以在支持深度网络全局优化训练的同时,保持硬件执行的高效率。
针对这一挑战,研究团队创新性地设计了一款支持完整反向传播训练流程的多核神经拟态芯片架构,实现了如下研究亮点:
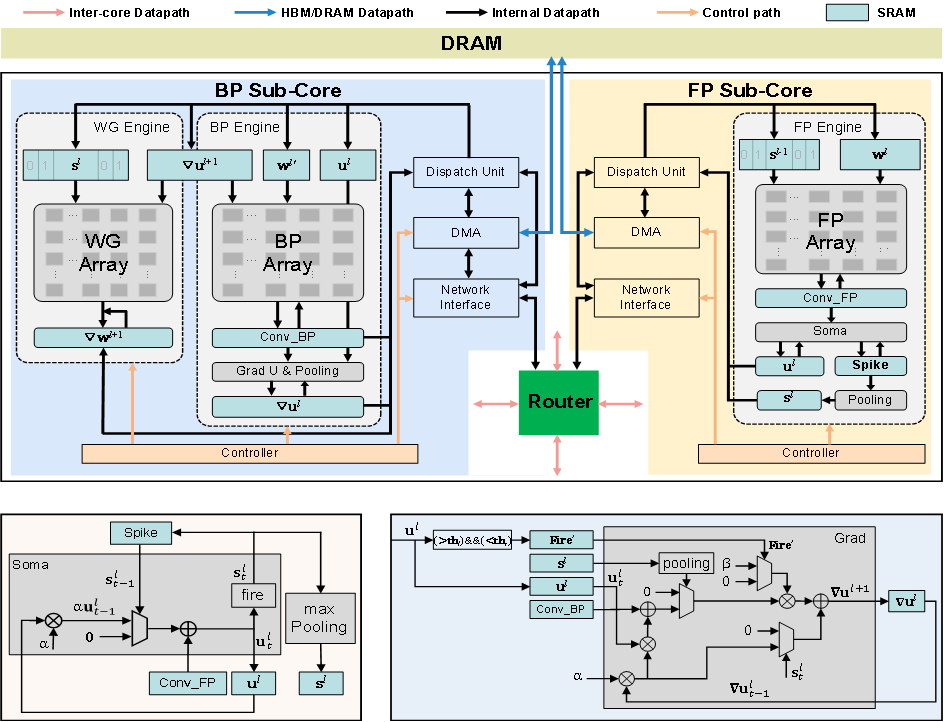
(1)首创可训练深度SNN的多核神经拟态架构:集成了前向传播、反向传播和权重梯度三个专用引擎的计算核,并通过2D Mesh网络进行互联,首次实现了将整个深度脉冲神经网络模型分布式部署在多核上,以执行基于反向传播的高效训练;
(2)实现核间与核内多层次并行加速:开发了细粒度的多层次并行计算策略,在核间对不同网络层进行流水线并行计算,在核内使三个引擎并行工作,显著提升了训练任务的吞吐效率;
(3)通过稀疏感知电路与数据流优化实现高能效:在所有计算引擎中均引入稀疏感知电路,充分利用训练中的信号稀疏性以跳过冗余操作,并配合定制数据流与脉冲数据单比特存储,从而显著降低了训练过程的能耗与片外内存访问量。
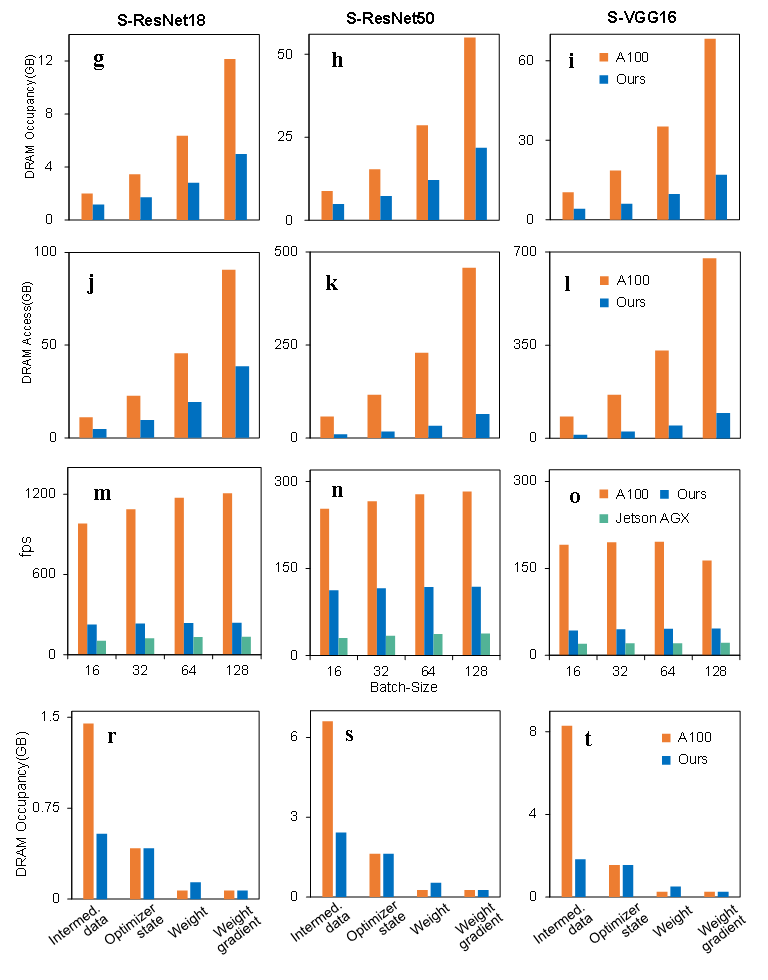
通过深度优化的架构设计,本架构在训练过程中显著降低了对外部存储的访问需求,其DRAM访问量相比英伟达A100 GPU减少55%至85%。在典型视觉模型训练任务中,该架构的性能达到边缘计算平台Jetson AGX Orin的1.9至3.3倍,并在28纳米工艺下实现了1.05 TFLOPS/W(FP16精度)的优异能效表现。
为验证该架构的可行性,团队基于FPGA成功实现了多核原型系统,并配套开发了相应的软件工具链。利用20核系统,研究人员成功从零开始训练出用于图像分类的深度脉冲神经网络,在精度上与GPU训练结果相当,并实现了高能效。进一步地,在智慧交通场景中,FPGA原型系统能够在无需云端支持的情况下,通过持续学习快速识别新增交通标志,也可基于联邦学习方法在保护各节点数据隐私的前提下协同优化模型。这充分证明了该架构在需实时适应、注重隐私保护的现实边缘环境中具备良好的应用潜力。
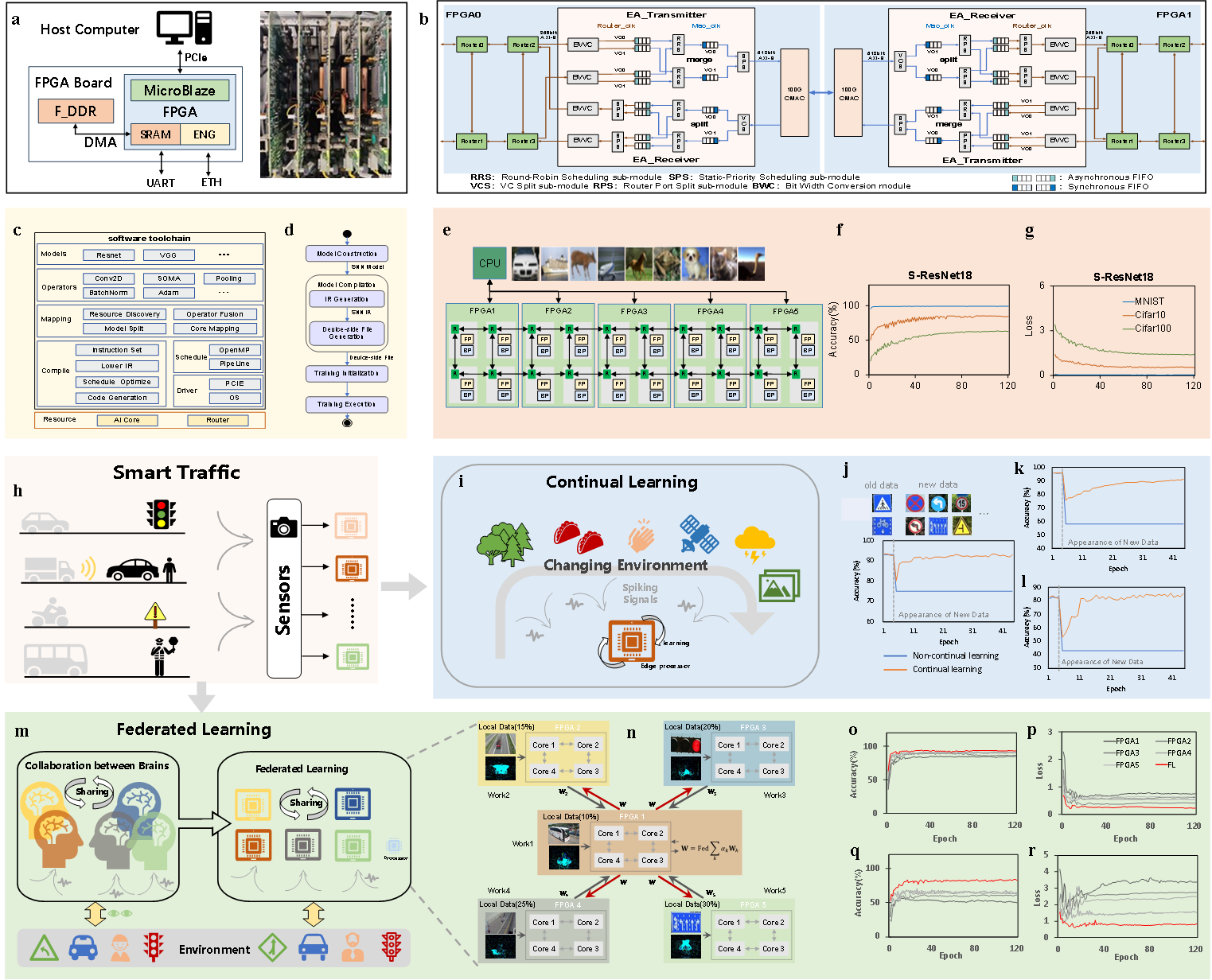
该研究将神经拟态架构的能力边界拓展至高效的全局训练,显著提升了训练效能,使其在资源受限的边缘可学习场景中具备更大的应用潜力,有助于实现真正能够自主适应、持续优化的边缘智能系统。
北京大学田永鸿教授、鹏城实验室周晖晖研究员、中国科学院自动化所李国齐研究员、北京大学崔小欣教授为论文的共同通讯作者。该研究获得了深圳市科技计划、国家自然科学基金、鹏城实验室重大攻关项目的资助。